The “Part 2” post ended up on an error on calling trainer.train, with incompatible tensor dimensions in a tensor multiplication. It was not clear at all (to me) what the root issue was. After getting back to basics and looking at the HF Text classification how-to, I noticed that my Dataset contained pytorch tensors or lists thereof, where the how-do just had simple data types.
Long story short, I removed the tokernizer’s parameter return_tensors="pt", and did not call tok_ds.set_format("torch"), and surprised, it worked. I had added these because the initial trial complained about a mix of GPU and CPU data.
Plan
At this stage, it is worthwhile laying out a roadmap of where this line of work may go:
Complete a classification on at least a subset of the Namoi dataset (this post)
kept = [x in labels_kept for x in litho_classes]litho_logs_kept = litho_logs[kept].copy() # avoid warning messages down the track.labels = ClassLabel(names=labels_kept)int_labels = np.array([ labels.str2int(x) for x in litho_logs_kept[MAJOR_CODE].values])int_labels = int_labels.astype(np.int8) # to mimick chapter3 HF so far as I can seelitho_logs_kept[MAJOR_CODE_INT] = int_labels
ds = Dataset.from_pandas(litho_logs_kept_mini_subset)def tok_func(x):return tokz( x[DESC], padding="max_length", truncation=True, max_length=max_length,# return_tensors="pt", ## IMPORTANT not to use return_tensors="pt" here, perhaps conter-intuitively )
Parameter 'function'=<function tok_func at 0x7f49f6e17a60> of the transform datasets.arrow_dataset.Dataset._map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.
# NOTE: the local caching may be superflousp = Path("./model_pretrained")model_name = p if p.exists() else STARTING_MODELmodel = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=num_labels, max_length=max_length)# label2id=label2id, id2label=id2label).to(device) ifnot p.exists(): model.save_pretrained(p)
# Keep the description column, which will be handy later despite warnings at training time.tok_ds = tok_ds.remove_columns(['__index_level_0__'])# tok_ds = tok_ds.remove_columns(['Description', '__index_level_0__'])
# Not sure why, but cannot set the labels class otherwise `train_test_split` complains# tok_ds.features['labels'] = labelsdds = tok_ds.train_test_split(test_size=0.25, seed=42)
# Defining the Trainer to compute Custom Loss Function, adapted from [Simple Training with the 🤗 Transformers Trainer, around 840 seconds](https://youtu.be/u--UVvH-LIQ?t=840)class WeightedLossTrainer(Trainer):def compute_loss(self, model, inputs, return_outputs=False):# Feed inputs to model and extract logits outputs = model(**inputs) logits = outputs.get("logits")# Extract Labels labels = inputs.get("labels")# Define loss function with class weights loss_func = torch.nn.CrossEntropyLoss(weight=class_weights)# Compute loss loss = loss_func(logits, labels)return (loss, outputs) if return_outputs else loss
output_dir ="./hf_training"batch_size =64# 128 causes a CUDA out of memory exception... Maybe I shoudl consider dynamic padding instead. Later.epochs =3# low, but for didactic purposes will do.lr =8e-5# inherited, no idea whether appropriate. is there an lr_find in hugging face?
The above nay not be strictly necessary, depending on your version of transformers. I bumped into the following issue, which was probably the transformers 4.11.3 bug: RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument index in method wrapper__index_select)
The following columns in the training set don't have a corresponding argument in `DebertaV2ForSequenceClassification.forward` and have been ignored: Description. If Description are not expected by `DebertaV2ForSequenceClassification.forward`, you can safely ignore this message.
/home/abcdef/miniconda/envs/hf/lib/python3.9/site-packages/transformers/optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(
***** Running training *****
Num examples = 23185
Num Epochs = 3
Instantaneous batch size per device = 64
Total train batch size (w. parallel, distributed & accumulation) = 64
Gradient Accumulation steps = 1
Total optimization steps = 1089
[1089/1089 04:57, Epoch 3/3]
Epoch
Training Loss
Validation Loss
F1
1
No log
0.072295
0.983439
2
No log
0.063188
0.985492
3
No log
0.061934
0.986534
The following columns in the evaluation set don't have a corresponding argument in `DebertaV2ForSequenceClassification.forward` and have been ignored: Description. If Description are not expected by `DebertaV2ForSequenceClassification.forward`, you can safely ignore this message.
***** Running Evaluation *****
Num examples = 7729
Batch size = 128
Saving model checkpoint to ./hf_training/checkpoint-500
Configuration saved in ./hf_training/checkpoint-500/config.json
Model weights saved in ./hf_training/checkpoint-500/pytorch_model.bin
tokenizer config file saved in ./hf_training/checkpoint-500/tokenizer_config.json
Special tokens file saved in ./hf_training/checkpoint-500/special_tokens_map.json
The following columns in the evaluation set don't have a corresponding argument in `DebertaV2ForSequenceClassification.forward` and have been ignored: Description. If Description are not expected by `DebertaV2ForSequenceClassification.forward`, you can safely ignore this message.
***** Running Evaluation *****
Num examples = 7729
Batch size = 128
Saving model checkpoint to ./hf_training/checkpoint-1000
Configuration saved in ./hf_training/checkpoint-1000/config.json
Model weights saved in ./hf_training/checkpoint-1000/pytorch_model.bin
tokenizer config file saved in ./hf_training/checkpoint-1000/tokenizer_config.json
Special tokens file saved in ./hf_training/checkpoint-1000/special_tokens_map.json
The following columns in the evaluation set don't have a corresponding argument in `DebertaV2ForSequenceClassification.forward` and have been ignored: Description. If Description are not expected by `DebertaV2ForSequenceClassification.forward`, you can safely ignore this message.
***** Running Evaluation *****
Num examples = 7729
Batch size = 128
Training completed. Do not forget to share your model on huggingface.co/models =)
This part is newer compared to the previous post, so I will elaborate a bit.
I am not across the high level facilities to assess model predictions (visualisation, etc.) so what follows may be sub-optimal and idiosyncratic.
test_pred = trainer.predict(trainer.eval_dataset)
The following columns in the test set don't have a corresponding argument in `DebertaV2ForSequenceClassification.forward` and have been ignored: Description. If Description are not expected by `DebertaV2ForSequenceClassification.forward`, you can safely ignore this message.
***** Running Prediction *****
Num examples = 7729
Batch size = 128
This is lower level than I anticipated. The predictions array appear to be the logits. Note that I was not sure label_ids was, and it is not the predicted label, but the “true” label.
light grey medium to coarse sandy gravel - 30%, and gravelly clay - 70%. gravel mainly basalt and jasper
24
CLAY
SDCY
sandy clay
25
SDSN
CLAY
none
26
GRVL
SAND
sand and gravel
27
SAND
SOIL
soil + sand
28
UNKN
CLAY
none
29
SHLE
CLAY
brown
30
CLAY
SAND
clayey sand (brown) - fine-medium
31
UNKN
CLAY
white puggy some slightly hard
32
GRNT
CLAY
none
33
SHLE
CLAY
none
34
BSLT
CLAY
none
35
GRVL
CLAY
none
36
SHLE
CLAY
none
37
CLAY
SDCY
sandy and gravel aquifer with bands of clay
38
SDCY
CLAY
clay sandy
39
CLAY
SDSN
silty
40
CLAY
SDCY
sandy clay, light grey, fine
41
BSLT
SHLE
blue bassalt
42
CLAY
SDCY
sandy brown clay
43
CLAY
SAND
sand - silty up to 1mm, clayey
44
SOIL
CLAY
none
45
GRVL
SAND
wash alluvial
46
CLAY
SDCY
sandy clay
47
GRNT
CLAY
none
48
UNKN
CLAY
none
49
SDSN
SAND
sand - mostly white very fine to very coarse gravel
50
GRVL
CLAY
gravelly sandy clay
51
SOIL
CLAY
none
52
BSLT
SDSN
brown weathered
53
GRVL
SAND
brown sand and fine gravel
54
GRVL
SAND
course sand and gravel, w/b
55
SDCY
GRNT
silt, sandy/silty sand
56
TPSL
BSLT
blue basalt
57
GRVL
CLAY
stones clay
58
ROCK
CLAY
ochrs yellow
59
GRVL
ROCK
stone, clayed to semi formed sandstone
60
UNKN
SAND
soak water bearing
61
BSLT
SDSN
balsalt: weathered
62
SOIL
CLAY
none
63
UNKN
CLAY
very
64
GRVL
CLAY
gravelly sandy clay
65
SDSN
GRNT
granite sand
66
SHLE
CLAY
none
67
ROCK
UNKN
water bearing
68
BSLT
SAND
h/frac, quartz
69
MDSN
COAL
coal 80% & mudstone, 20%; dark grey, strong, carbonaceous
70
GRVL
CLAY
as above
71
CLAY
GRVL
gravelly clay
72
GRVL
SAND
sand + gravel (water)
73
CLAY
GRVL
with gravel
74
SAND
SDCY
sandy yellow
75
CLAY
SOIL
brown soil and clay
76
CLAY
SDCY
sandy clay
77
UNKN
CLAY
hard slightly stoney
78
SDSN
CLAY
none
79
SDSN
ROCK
sandsstone
80
TPSL
CLAY
none
81
SOIL
CLAY
none
82
SHLE
BSLT
shae (brown)
83
BSLT
CLAY
none
84
CLAY
SDCY
sandy clay
85
SAND
SOIL
surface soil
86
GRVL
CLAY
none
87
SAND
CLAY
none
88
SDSN
CLAY
none
89
CLAY
SHLE
grey
90
SDCY
CLAY
clay sandy water supply
91
GRVL
BSLT
blue/dark mixed
92
GRVL
SAND
sand + gravel + white clay
93
UNKN
SHLE
grey very hard
94
UNKN
CLAY
white fine, and clay, nodular
95
CLAY
SLSN
yellow clayey siltstone
96
SDSN
CLAY
none
97
SDSN
SAND
brown sand + stones (clean)
98
SDSN
CLAY
yellow
99
BSLT
UNKN
broken
100
CLAY
SDCY
sandy clay stringers
101
SAND
CLAY
none
102
SDSN
ROCK
bedrock - sandstone; whitish greyish blue, highly weathered, fine grains, angular to subangular, predominantly clear quartz. very small amounts of...
103
TPSL
CLAY
none
Observations
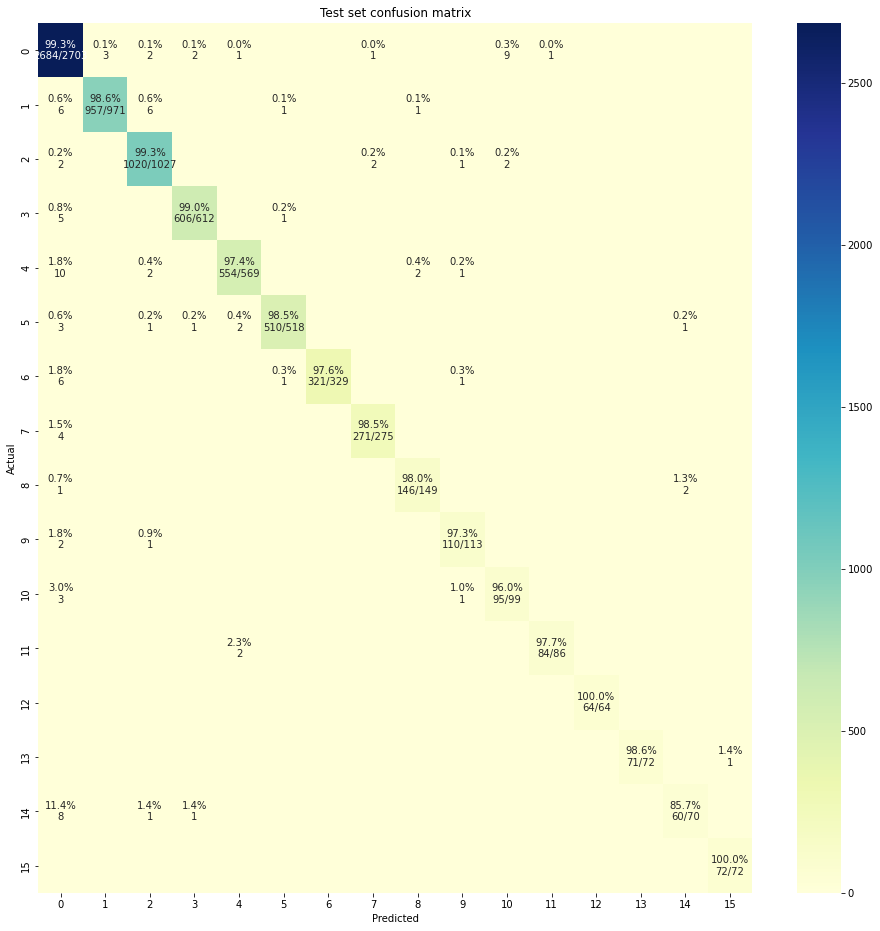
The error rate is rather low for a first trial, though admittedly we know that many descriptions are fairly unambiguous. If we examine the failed predictions, we can make a few observations:
There are many none descriptions that are picked up as CLAY, but given that the true labels are not necessarily UNKN for these, one cannot complain too much about the model. The fact that some true labels are set to CLAY for these hints at the use of contextual information, perhaps nearby lithology log entries being classified as CLAY.
The model picks up several sandy clay as SDCY, which is a priori more suited than the true labels, at least without other information context explaining why the “true” classification ends up being another category such as CLAY
Typographical errors such as ssandstone are throwing the model off, which is extected. A production pipeline would need to have an orthographic correction step.
grammatically unusual expressions such as clay sandy and clayey/gravel brown are also a challenge for the model.
More nuanced descriptions such as light grey medium to coarse sandy gravel - 30%, and gravelly clay - 70%. gravel mainly basalt and jasper where a human reads that the major class is clay, not gravel, or broken rock is more akin to gravel than rock.
Still, the confusion matrix is overall really encouraging. Let’s have a look:
import seaborn as snsfrom matplotlib.ticker import FixedFormatterdef plot_cm(y_true, y_pred, title, figsize=(10,10), labels=None):'''' input y_true-Ground Truth Labels y_pred-Predicted Value of Model title-What Title to give to the confusion matrix Draws a Confusion Matrix for better understanding of how the model is working return None ''' cm = confusion_matrix(y_true, y_pred, labels=np.unique(y_true)) cm_sum = np.sum(cm, axis=1, keepdims=True) cm_perc = cm / cm_sum.astype(float) *100 annot = np.empty_like(cm).astype(str) nrows, ncols = cm.shapefor i inrange(nrows):for j inrange(ncols): c = cm[i, j] p = cm_perc[i, j]if i == j: s = cm_sum[i] annot[i, j] ='%.1f%%\n%d/%d'% (p, c, s)elif c ==0: annot[i, j] =''else: annot[i, j] ='%.1f%%\n%d'% (p, c) cm = pd.DataFrame(cm, index=np.unique(y_true), columns=np.unique(y_true)) cm.index.name ='Actual' cm.columns.name ='Predicted' fig, ax = plt.subplots(figsize=figsize) ff = FixedFormatter(labels) ax.yaxis.set_major_formatter(ff) ax.xaxis.set_major_formatter(ff) plt.title(title) sns.heatmap(cm, cmap="YlGnBu", annot=annot, fmt='', ax=ax)def roc_curve_plot(fpr,tpr,roc_auc): plt.figure() lw =2 plt.plot(fpr, tpr, color='darkorange', lw=lw, label='ROC curve (area = %0.2f)'%roc_auc) plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('Receiver operating characteristic example') plt.legend(loc="lower right") plt.show()
plot_cm(y_true, y_pred, title="Test set confusion matrix", figsize=(16,16), labels=labels.names)
/tmp/ipykernel_29992/2038836972.py:37: UserWarning: FixedFormatter should only be used together with FixedLocator
ax.yaxis.set_major_formatter(ff)
/tmp/ipykernel_29992/2038836972.py:38: UserWarning: FixedFormatter should only be used together with FixedLocator
ax.xaxis.set_major_formatter(ff)
Conclusion, Next
Despite quite a few arbitrary shortcuts in the overall pipeline, we have a working template to fine-tune a pre-trained classification model to classify primary lithologies.
I’ll probably have to pause on this work for a few weeks, though perhaps a teaser Gradio app on Hugging Face spaces in the same vein as this one is diable with relatively little work.
Appendix
# Later on, in another post, for predictions on the CPU:# model_cpu = model.to("cpu")# from transformers import TextClassificationPipeline# tokenizer = tokz# pipe = TextClassificationPipeline(model=model_cpu, tokenizer=tokenizer, return_all_scores=True)# # outputs a list of dicts like [[{'label': 'NEGATIVE', 'score': 0.0001223755971295759}, {'label': 'POSITIVE', 'score': 0.9998776316642761}]]# pipe("clayey sand")# raw_inputs = [# "I've been waiting for a HuggingFace course my whole life.",# "I hate this so much!",# ]# inputs = tokz(raw_inputs, padding=True, truncation=True, return_tensors="pt")# print(inputs)# pipe("I've been waiting for a HuggingFace course my whole life.")