Background
Since this previous post I’ve been looking at massaging the API and sample information in swift2 - python package to a markdown format balancing information content and size.
Resources
I know of https://web2md.answer.ai/ which is a nifty tool to convert web pages to markdown as a starting point. It produces some surprisingly good output at a first glance, but there is a bit of cruft I would like to remove. It may be feasible and one can always automate, but can we avoid this additional wrangling due to intermediary HTML designed for human eyes?
The swift2 - python package site is generated using mkdocs with mkdocstrings in particular to extract python docstrings information. I was wondering whether there was an option to produce directly markdown. Enter griffe2md, which looks exactly like what I need.
Steps
Trying griffe2md
I have uv installed at user level but globally. I take a punt that griffe2md will be useful as a global tool as well rather than hidden in a python venv:
uv tool install griffe2mdLet’s go and see what happens:
griffe2md ~/src/swift/bindings/python/swift2/ -o swift2_api.mdThis works quite fast. Some warnings about missing annotations, useful in its own way. The output is a file with 30,000 lines. It appears it has also parsed notebooks and tests, and more, besides the package itself. Fair enough.
The markdown output appears syntactically sound, and renders well via VSCode. Not sure about the anchors, but we will be finessing if and when we need.
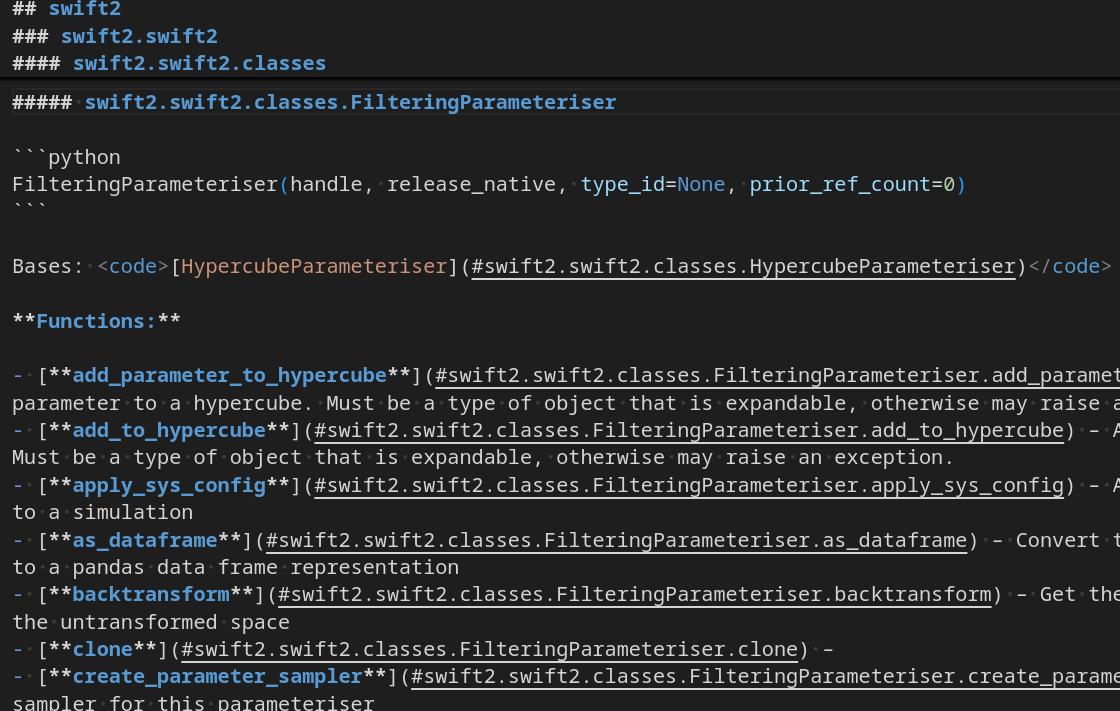
API focus
Let’s focus on the package itself this time. For the notebooks, we may use something else namely nbconvert
griffe2md ~/src/swift/bindings/python/swift2/swift2/ -o swift2_api.mdWe have a 677K document with 19,000 lines. Not sure what this means in terms of tokens for an LLM. Noted, but I don’t want to preempt removing information unless warranted or needed.
So, what’s next?
Back to my examplar
In the SWIC lesson 16 that inspired me, Jeremy Howard demonstrated how to massage the cloudflare-python API to a useful LLM context. This has an api.md document that happens to be about the same file size as mine, and 10,000 lines, with the caveat that I am not quite comparing apples with apples. Be it as it may, it reinforces the impression that “my” modelling API is indeed substantial. Jeremy assessed the raw document would be too large for the LLM context.
Let’s see if I can adapt the markdown API data massaging to my context.
Let’s use BeautifulSoup:
uv venv --python=3.11
. .venv/bin/activateuv pip install beautifulsoup4
Let’s register a kernel to work from a notebook, without reinstalling jupyter-lab
uv pip install ipykernel
python -m ipykernel install --user --name hydrobuddy --display-name "hydrobuddy"Using solveit
The examplar from which I start is a notebook running on solveit. I will stick to that platform to adapt it in the first place, as it uses some unique features for providing context to the AI service.
To be continued in a follow up post…