Context
Last week, besides being my birthday, saw the announce of SmolLM3: smol, multilingual, long-context reasoner. Lots of reasons, professional and personal interest, to try it. Let’s go!
Upfront Acknowledgments
A big applause to the team behind SmolLM3, really impressive work, and truly open.
Log
I still have a Quadro RTX 4000 with 8GB VRAM, and glad I invested in it a few years ago. Let’s see if I can run SmolLM3 on it.
setting up the python environment
I am not quite logging my iterative process installing smollm3 dependencies; unsurpringly installing stuff on top of pytorch/cuda was a bit bumpy, though not as bad as I have experienced in the past.
The smolLM3 setup instrucitons only refer to uv pip install -U transformers (I re-use an environment created with uv), but running sample code then complains about the lack of pytorch.
I had a Debian Linux with a stack for cuda at version 12.9. The pytorch instructions seemed to max out at cuda 12.8 currencly. So, downgraded via synaptic, just in case. It is unclear whether the python env will be self contained or not.
uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
Base trial according to smollm3 HF page
Then trying:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "HuggingFaceTB/SmolLM3-3B"
device = "cuda" # for GPU usage or "cpu" for CPU usage
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
).to(device)But this maxes out the VRAM. I was not expecting this from a 3 billon parameter model. I need to use a smaller type for torch_dtype (according to copilot…)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
attn_implementation="flex_attention",
).to(device)Important Note* attn_implementation="flex_attention" will prove to be slowing things down a fair bit, which I discover afterwards. I had gotten to use that when first figuring out something and bumped into issues with using flash attention, see later in the quantization trial.
This uses 6.478GB out of 8.000GB. Let’s try a prompt, and time to get the token rate:
prompt = "Give me a brief explanation of gravity in simple terms."
messages_think = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages_think,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Generate the output
import datetime
a=datetime.datetime.now()
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
b=datetime.datetime.now()
d=b-amodel.generate triggers the following warning
.venv/lib/python3.11/site-packages/torch/_inductor/compile_fx.py:2177: UserWarning: Quadro RTX 4000 does not support bfloat16 compilation natively, skipping
warnings.warn(# Get and decode the output
output_ids = generated_ids[0][len(model_inputs.input_ids[0]) :]
ntk = len(output_ids)
tks_per_second = ntk/d.total_seconds()
print(f"Generated at {tks_per_second:.2f} tokens per second")Generated at 6.69 tokens per second. Not too bad, not stellar, but given the warning about no native support, may be the best on that GPU.
Without specifying attn_implementation
I later on tried creating the model with the following arguments:
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
# attn_implementation="flex_attention"
).to(device)This led to a Generated at 28.90 tokens per second. I am not sure which default args and interplay between them for AutoModelForCausalLM.from_pretrained, but as flagged previously, this is quite a difference in generation rate. Also, I observe that the GPU usage rate is higher than attn_implementation="flex_attention" which was a third.
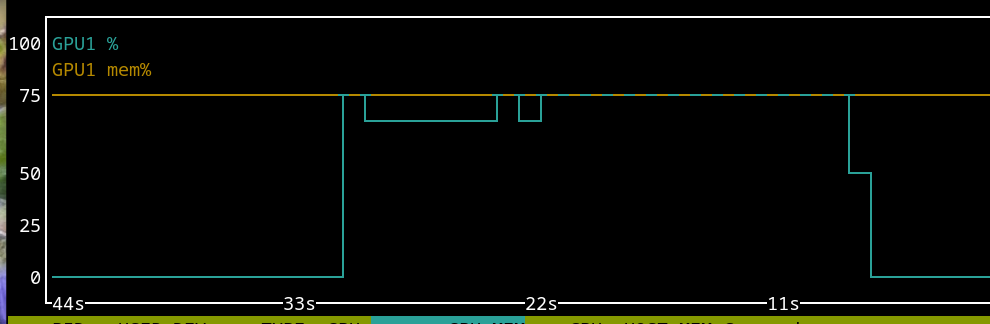
Quantizing
The transformer - SmolLM3 doc page has a section on quantization. Let’s see what memory footprint and token rate we can get with that setup. That doc page only hinted at the need to do pip install flash-attn --no-build-isolation, but I found out the following was necessary.
uv pip install wheel
uv pip install flash-attn --no-build-isolation
uv pip install accelerate bitsandbytesHowever, flash-attn version 2 or 3 (latter currently in beta) do not support (yet) the Turing architecture of my GPU. Too old.
I tried to downgrade with uv pip install flash-attn==1.0.9 --no-build-isolation, but then it is transformers that cannot handle flash-attn below version 2. There is a flash-attention-turing lifesaver, but I felt I was running out of time to try this.
So, instead trying other options for the attention implementation, presumably slower ones.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_name = "HuggingFaceTB/SmolLM3-3B"
device = "cuda" # for GPU usage or "cpu" for CPU usage
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
quantization_config=quantization_config,
# attn_implementation="flash_attention_1" # transformers complains and provides 4 possible choices, including
attn_implementation="flex_attention"
).to(device)VRAM is 3.706Gi/8.000Gi, below 50%.
Let’s query about gravity, same as previous trial. I note that the GPU is only used to the tune of about one third of its capacity somehow, it was about the same without quantization, now that I think about it.
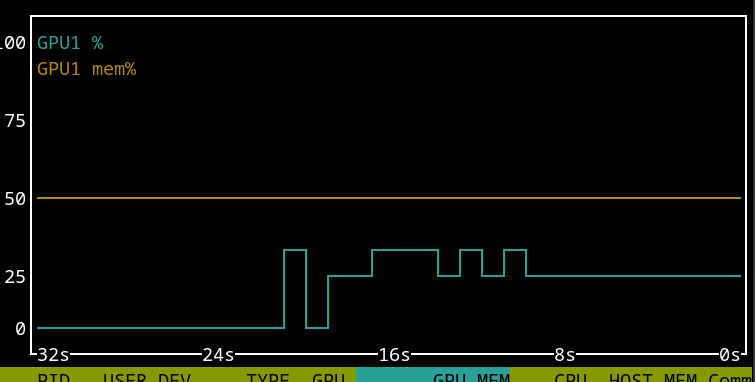
The result is Generated at 5.78 tokens per second.
quantized, but without specifying attn_implementation
I later on tried creating the model with the following arguments:
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
quantization_config=quantization_config,
trust_remote_code=True,
# not clear what the default attn_implementation is used, but disable the following:
# attn_implementation="flex_attention"
).to(device)This led to a Generated at 16.15 tokens per second, and the GPU usage is closer to 50 to 60 percent:

attn_implementationI do a quick check not specifying a value for the argument trust_remote_code, and this seems not cause have any change in the generation rate.
Stocktake
On the plus side, it works rather well, after a discovery phase. Main lesson is that the arguments passed to AutoModelForCausalLM.from_pretrained can really make a difference in performance, at the least the argument attn_implementation. The token rate and GPU usage can be low, not a snail pace, but below fast reading. The best rate of generation at 28 tokens per second is pretty good to me on an older harware. See SmolLM3 has day-zero support in mlx-lm and it’s blazing fast [190tk/s] on an M4 Max for a higher water mark, but then again very different hardware.
Perhaps I could squeeze out a few more tokens per seconds if I could get a flash attention implementation working, but this looks a low-level hack for now.